Coarse Grained Reconfiurable Architectures (CGRAs):
Recently, the increasing speed and performance requirements of multimedia processing and mobile telecommunication applications, coupled with the demands for flexibility and low non-recurring engineering costs, have made reconfiurable hardware a very popular implementation platform. The reconfiurable architectures can be classified on the basis of granularity i.e. number of bits that can be explicitly manipulated. Coarse Grained Reconfigurable Architectures (CGRAs), provide operator level confiurable functional blocks, word level datapaths, and very area-
efficient routing switches. Therefore, compared to the fine-grained architectures (like FPGAs), CGRAs require lesser confiuration memory and confiuration time (two or more orders of magnitude). As a result, CGRAs achieve a signifiant reduction in area and energy consumed per computation, at the cost of a loss in flexibility compared to bit-level operations. Therefore, CGRAs have been a subject of intensive research since the last decade [1]-[6].
System Overview:
Our CGRA has been developed based on the the Dynamically Reconfigurable Resource Array (DRRA). As depicted in Fig. 1, it is composed of three main components: (i) system controller, (ii) computation layer , and (iii) memory layer . For each hosted application, a separate partition can be created in memory and computation layers. The partition is optimal in terms of energy, power, and reliability [1]-[6].
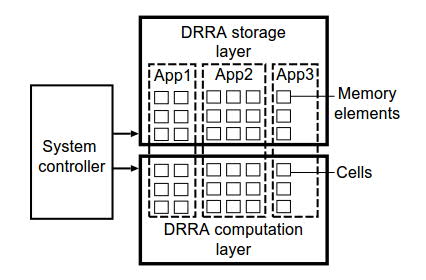
Fig. 1. Different applications executing on the DRRA.
System controller: Fig. 2 illustrates the overall system architecture for managing DRRA. The controlling intelligence provided by a Run-Time resource Manager (RTM). The RTM resides in the LEON 3 processor and has two main responsibilities: (i) to configure DRRA by loading the binary from the configuration memory, and (ii) to parallelize/serialize application tasks, depending on the deadlines. Before our modifications, the application to component mapping was done at compile-time. While the architecture accommodated runtime parallelism, it did
not allow to dynamically remap an implementation.
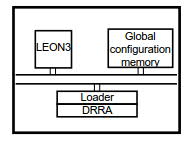
Fig. 2. System management layer of DRRA.
DRRA computation layer: DRRA computational layer is shown in Fig. 3. It is composed of four elements: (i) Register files (reg-files), (ii) morphable Data Path Units (DPUs), (iii) circuit-Switched Boxes (SBs), and (iv) sequencers. The reg-files store data for DPUs. The DPUs are functional units responsible for performing computations. SBs provide interconnectivity between different components of DRRA. The sequencers hold the configware which corresponds to the configuration of the reg-files, DPUs, and SBs. Each sequencer can store up to 64 36-bit instructions and can reconfigure the elements only in its own cell. As shown in Fig. 3, a cell consists of a Reg-file, a DPU, SBs, and a sequencer, all having the same row and column number as a given cell. The configware loaded in the sequencers contains a sequence of instructions (reg-file, DPU, and SB instructions) that implements the DRRA program.
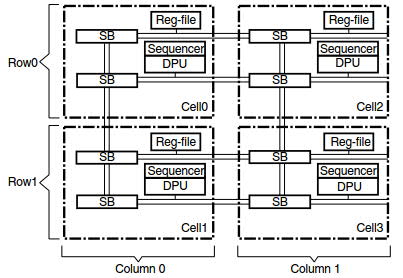
Fig. 3. DRRA computation layer.
DRRA storage layer: Memory layer is a distributed scratch pad (data/configware) memory that complements DRRA with a scalable memory architecture. Its distributed nature allows a high speed data and configware access to the DRRA computational layer (compared to the global configuration memory).
DRRA con figuration flow:
As shown in Figure 4, DRRA is programmed in two phases (off-line and on-line). The configware (binary) for commonly used DSP functions (FFT, FIR filter etc.) is written
either in VESYLA (HLS tool for DRRA) and stored in an off-line library. For each function, multiple versions, with different degree of parallelism, are stored. The library, thus created, is
probled with frequencies and worst case time of each version. To map an application, its (simulink type) representation is fed to the compiler. The compiler, based on the available
functions (present in library) constructs the binary for the complete application (e.g. WLAN). Since the actual execution times are unknown at compile-time, the compiler sends all
the versions (of each function), meeting deadlines, to the run-time configware memory. To reduce memory requirements for storing multiple versions, the compiler generates a compact representation of these versions. The compact representation is unraveled (parallelized/serialized) dynamically by the run-time resource manager (running on LEON3 processor).
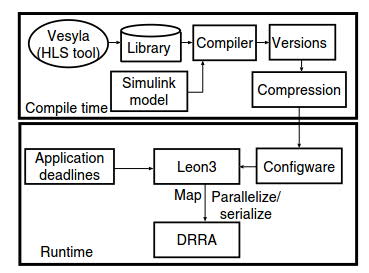
Fig. 4. Configuration model.
References:
- [1] S. M. A. H. Jafri, M. Daneshtalab, K. Paul, A. Hemani, H. Tenhunen, G. Serreno, and N. Abbas, “TransPar: Transformation Based Dynamic Parallelism for Low Power CGRAs,” in Proceedings of 24th IEEE International Conference on Field Programmable Logic and Applications (FPL), pp. 1-8, 2014, Germany. (25% acceptance rate)
- [2] S. M. A. H. Jafri, G. Serrano, J. Iqbal, M. Daneshtalab, A. Hemani, K. Paul, J. Plosila, H. Tenhunen, “RuRot: Run-time Rotatable-expandable Partitions for Efficient Mapping in CGRAs,” in Proceedings of 14th IEEE International Conference on Embedded Computer Systems: Architectures, MOdeling, and Simulation (SAMOS XIV), July 2014, pp. 233-241, Greece. (25% acceptance rate)
- [3] S. M. A. H. Jafri, A. Tajammul, M. Daneshtalab, A. Hemani, K. Paul, J. Plosila, P. Erville, H. Tenhunen, “ Customizable Compression Architecture for Efficient Configuration in CGRAs,” in Proceedings of The 22nd Annual IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), pp. 31, 2014, USA. (25% acceptance rate)
- [4] S. M. A. H. Jafri, M. A. Tajammul, M. Daneshtalab, A. Hemani, K. Paul, P. Ellervee, J. Plosila, H. Tenhunen, “Morphable Compression Architecture for Efficient Configuration in CGRAs,” in Proceedings of 17th IEEE Euromicro Conference On Digital System Design (DSD), pp. 42-49, 2014, Italy.
- [5] S. M.A.H. Jafri, M. Daneshtalab, A. Hemani, N. Abbas, M. A. Awan, J. Plosila, “TEA: Timing and Energy Aware compression architecture for Efficient Configuration in CGRA,” Elsevier Journal of Microprocessors and Microsystems (MICPRO-Elsevier), Vol. 39, No. 8, pp. 973-986, 2015.
- [6] S. M.A.H. Jafri, M. Daneshtalab, N. Abbas, G. Serrano, A. Hemani, “TransMap: Transformation Based Remapping and Parallelism for high utilization and energy efficiency in CGRAs,” IEEE Transaction on Computers (IEEE-TC). (to appear) DOI: 10.1109/TC.2016.2525981
Back to main page |
