DeepMaker - Deep Learning Accelerator on Programmable Devices:
In recent years, deep neural networks (DNNs) has shown excellent performance on many challenging machine learning tasks, such as image classification, speech recognition, and unsupervised learning tasks. The Complex DNNs applications require a great amount of computation, storage, and memory bandwidth to provide a desirable trade-off between accuracy and performance which makes them not suitable to be deployed on resource-limited embedded systems. DeepMaker aims to provide optimized DNN models including Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) that are customized for deployment on resource-limited embedded hardware platforms. To customize DNN for resource-limited embedded platforms, we have proposed this framework, with the aim of automatic design and optimization of deep neural architectures using multi-objective Neural Architecture Search (NAS).
In the DeepMaker project [1][2][3], we have proposed novel architectures that are able to do inference in run-time on embedded hardware, while achieving significant speedup/ performance with negligible accuracy loss. Furthermore, to accelerate the inference of DNN on resource-limited embedded devices, we also consider using quantization techniques as one of the most popular and efficient techniques to reduce the massive amount of computations and as well the memory footprint and access in deep neural networks [4][5][6].
The bird’s eye view of the DeepMaker framework:
Figure 1 illustrates the bird’s eye view of the DeepMaker framework. DeepMaker automatically generates a robust DNN in terms of network accuracy and network size, then ports the generated DNN model to an embedded device. Unlike previous neural architectural solutions that their focuses are only on improving the accuracy level, DeepMaker also considers network complexity as the second objectives of the search space in order to adaptively find a fit DNN for limited resource embedded devices.
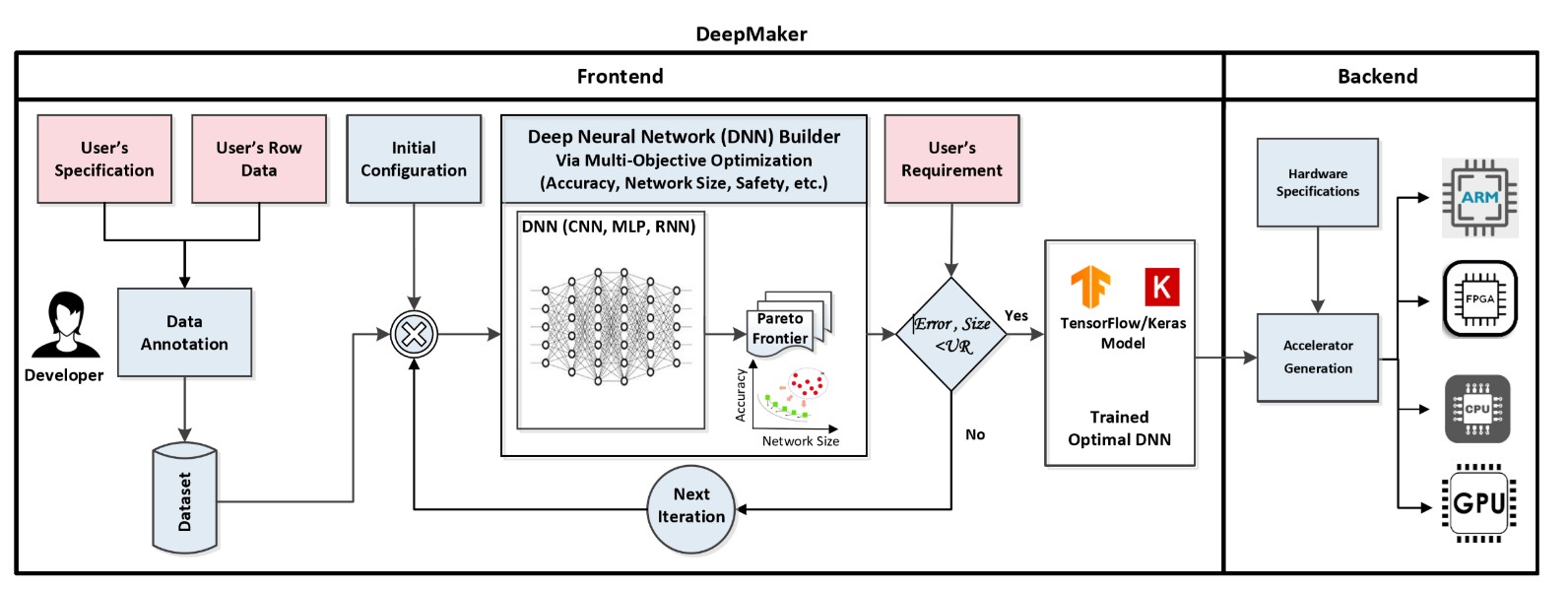
Fig. 1. The bird’s eye view of the DeepMaker framework.
Frontend: This stage aims at automating the procedure of hardware-aware DNN model design. It receives as inputs, a dataset, a set of user requirements (performance, memory, and energy consumption), and a library of DNN models. The output is a trained DNN with the required metrics (i.e. accuracy, energy consumption, performance) for the target architecture that will be propagated to next design steps. For this, DNN builder is equipped with a multi-objective optimization (MOO) toolbox to solve neural architecture search problem by finding a set of Pareto-optimal surfaces. The MOO starts exploring design space after setting predefined learning and optimization parameters. The optimization procedure will be continuing until satisfying user’s requirement or the maximum number of iterations is reached.
Backend: This stage aims at automating a system-level design process, partitioning, mapping, and scheduling the DNN model selected in the previous stage onto the target processing platform. This phase will be guided by cost models that take features and it will generate an architecture-aware partitioned, and mapped configuration ready to be transferred to the target accelerator. If the target technology is FPGA, this phase will first configure the template accelerator RTL code based on the target FPGA and the DNN model. Once the partitioning, mapping, and scheduling is done, a retargetable code generator will automate the porting of the inference application on the target architecture.
References:
- [1] M. Loni, S. Sinaei, A. Zoljodi, M. Daneshtalab, M. Sjödin, "DeepMaker: A Multi-Objective Optimization Framework for Deep Neural Networks in Embedded Systems," Elsevier Journal of Microprocessors and Microsystems (MICPRO-Elsevier), Vol. 73, 2020.
- [2] M. Loni, M. Daneshtalab, M. Sjödin, “ADONN: Adaptive Design of Optimized Deep Neural Networks for Embedded Systems,” in Proceedings of the 21st IEEE Euromicro Conference on Digital System Design (DSD), 2018, Czech.
- [3] M. Loni, A. Majd, A. Loni, M. Daneshtalab, M. Sjödin, E. Troubitsyna, “Designing Compact Convolutional Neural Network for Embedded Stereo Vision Systems,”
in Proceedings of the IEEE 12th International Symposium on Embedded Multicore/Many-core Systems-on-Chip(MCSoC), 2018, Vietnam. (Best paper award)
- [4] N. Nazari, S. A. Mirsalari, S. Sinaei, M. E. Salehi, M. Daneshtalab, “Multi-level Binarized LSTM in EEG Classification for Wearable Devices,”
in Proceedings of 28th IEEE Euromicro Conference on Parallel, Distributed and Network-Based Computing (PDP), 2020, Sweden.
- [5] N. Nazari, M. Loni, M. Salehi, M. Daneshtalab, M. Sjödin, “TOT-Net: An Endeavor Toward Optimizing Ternary Neural Networks,”
in Proceedings of the 22nd IEEE Euromicro Conference on Digital System Design (DSD), 2019, Greece.
Back to main page |
